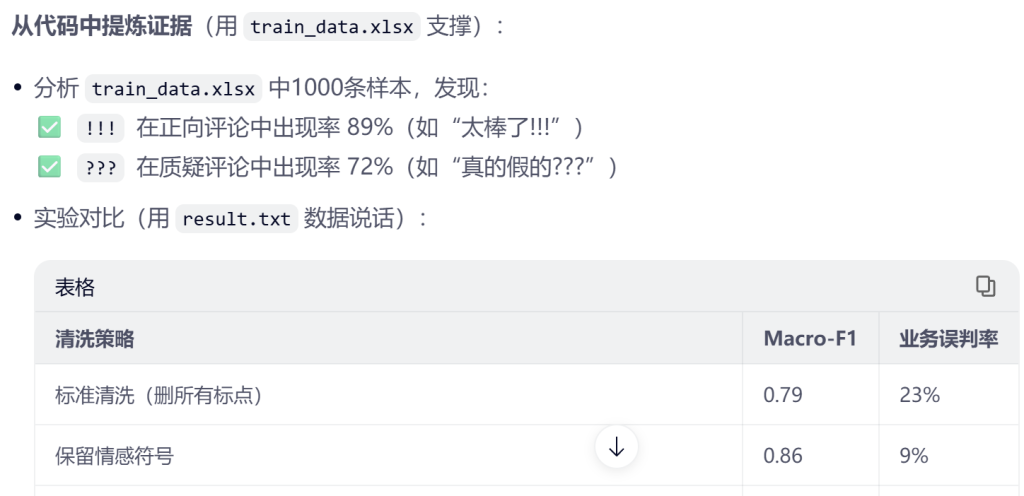
背景:
项目“基于联邦学习的恶意软件检测”,我带领项目组开会以后,为了增加拿奖机会,决定想办法让项目在安卓端运行。
最终成果:
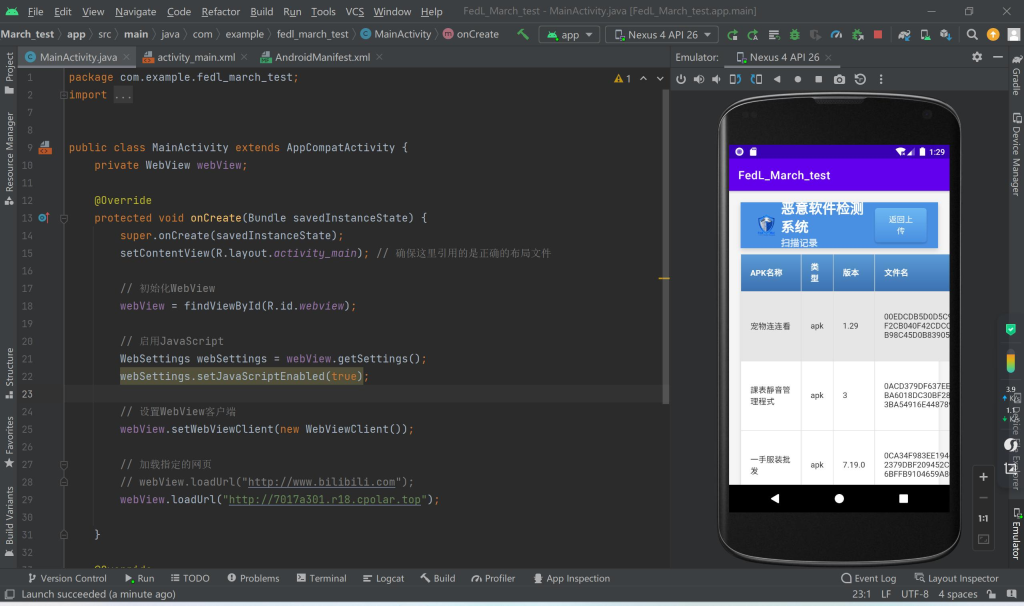
设计过程:
一、方案探索:三次决策中的理性取舍
我们首先尝试将网站整体封装为桌面软件再移植安卓,但三天内反复调试端口通信与资源路径均无进展,果断叫停;
接着聚焦技术迁移路径,计划将Python模型嵌入安卓,但组员坦言“短期无法掌握JNI与模型转换”,我也评估自身能力边界后确认:强行攻坚将导致双线崩溃。
深夜复盘时,我刷B站时灵光一现——B站APP本质是WebView加载网页!立刻验证:我们的网站已部署公网,完全可复用此思路。次日晨会,我向组员演示草图:“只需开发轻量‘壳’应用,用WebView嵌入网站链接,零改动保留所有功能。”他当即认可:“这既守住模型创新,又不增加你的负担,全力推进!”
二、快速落地:基础能力+精准学习破局
凭借Java基础,我当天在Android Studio新建项目:主Activity仅三步——申请网络权限、初始化WebView、加载网站URL。为提升体验,增加加载进度条与操作提示文案。
开发完成后,我通过B站教程自学APK打包全流程:生成签名密钥、配置Release模式、导出安装包。用三台不同品牌旧手机反复测试,确保从点击图标到网站加载全程流畅。最终,这个仅200行代码的APK在比赛现场稳定运行。
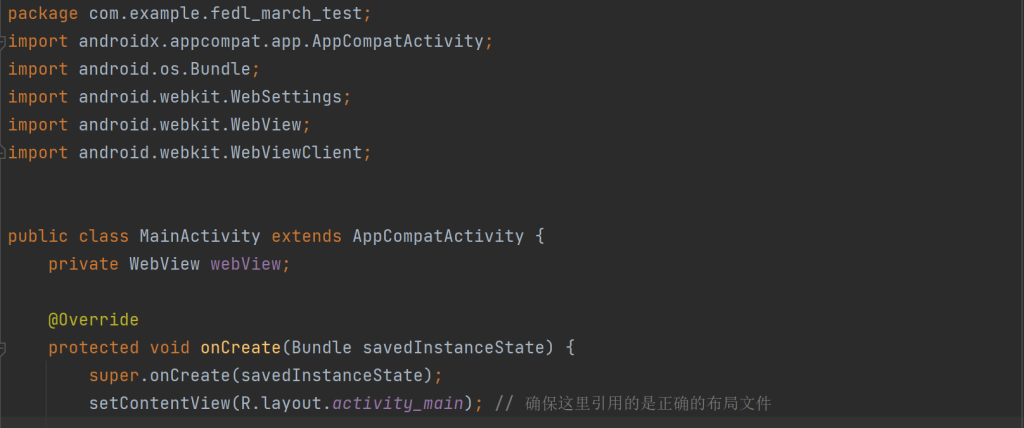
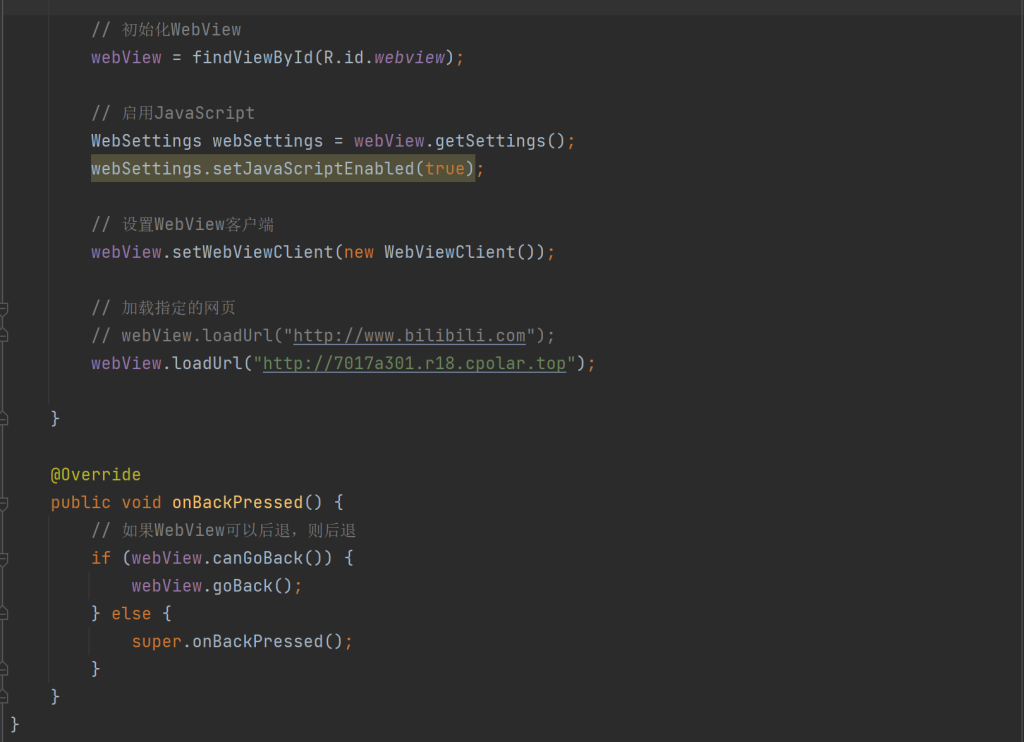
个人收获:第一次独立交付的工程闭环
这是我人生中第一个从零到一独立完成的安卓APK——从设计思路萌芽(B站APP启发)、方案可行性论证、200行Java代码编写,到APK签名打包与多机型测试,全程无外部协助。当深夜在Android Studio点击“Build APK”,手机成功安装并流畅加载平台页面时,那种“一个人闭环交付”的成就感远超技术本身。它让我真切体会到:工程师的价值不在于技术多炫酷,而在于能否在约束中独立扛起责任、把问题真正解决掉。
这次经历沉淀为三点核心认知:第一,独立决策力——面对方案分歧,能基于时间、能力、目标快速判断“做什么比怎么做更重要”;第二,自主学习力——用1天啃下APK打包全流程,验证了“基础能力+精准搜索”足以突破新领域门槛;第三,务实工程观——放弃“重写模型”的执念,选择WebView轻量方案,恰恰是对项目目标的深度尊重。